Operating System: Chapter 03 - 프로세스
초기의 컴퓨터 시스템은 한 번에 하나의 프로그램만을 실행하도록 허용하였으며, 그 프로그램이 시스템을 완전히 제어하고, 시스템의 모든 자원에 접근할 수 있었다.
오늘날의 컴퓨터 시스템은 메모리에 다수의 프로그램이 적재되어 병행 실행되는 것을 허용한다.
프로세스란 실행 중인 프로그램을 말하며, 현대의 컴퓨팅 시스템에서 작업의 단위이다.
3.1. 프로세스 개념
초창기 컴퓨터는 작업(job)을 실행하는 일괄처리 시스템이었고, 사용자 프로그램 또는 태스크(task)를 실행하는 시분할 시스템이 뒤를 이었다.
단일 사용자 시스템에서도 사용자는 워드프로세서, 웹 브라우저 및 전자메일 패키지와 같은 여러 프로그램을 한 번에 실행할 수 있다.
다중 태스킹을 지원하지 않는 임베디드 장치에서와 같이 컴퓨터가 한 번에 하나의 프로그램만 실행할 수 있더라도, 운영체제는 메모리 관리와 같은 자체 프로그램된 내부 활동을 지원해야 할 수도 있다.
여러 측면에서 이 모든 활동은 유사하며, 프로세스라고 부를 수 있다.
3.1.1. 프로세스
프로세스란 실행 중인 프로그램이다.
프로세스의 현재 활동 상태는 프로그램 카운터 값과 프로세서 레지스터의 내용으로 나타낸다.
프로세스의 메모리 배치는 일반적으로 여러 섹션으로 구분되며 다음과 같다.
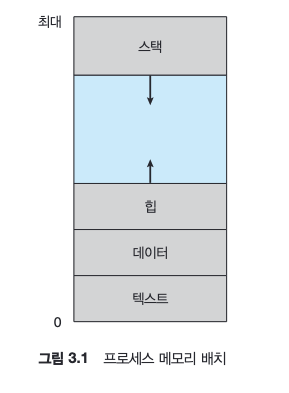
- 텍스트 섹션: 실행 코드
- 데이터 섹션: 전역 변수
- 힙 섹션: 프로그램 실행 중에 동적으로 할당되는 메모리
- 스택 섹션: 함수를 호출할 때 임시 데이터 저장장소(함수 매개변수, 복귀 주소 및 지역 변수)
텍스트 및 데이터 섹션의 크기는 고정되기 때문에 프로그램 실행 시간 동안 크기가 변하지 않는다.
힙과 스택 섹션은 프로그램 실행 중에 동적으로 줄어들거나 커질 수 있다.
함수가 호출될 때마다 함수 매개변수, 지역 변수 및 복귀 주소를 포함하는 활성화 레코드가 스택에 push되며, 함수에서 제어가 되돌아오면 스택에서 활성화 레코드가 pop된다.
마찬가지로 메모리가 동적으로 할당됨에 따라 힙이 커지고 메모리가 시스템에 반환되면 축소된다.
스택 및 힙 섹션이 서로의 방향으로 커지더라도 운영체제는 서로 겹치지 않도록 해야 한다.
프로그램 자체는 프로세스가 아니다. 프로그램은 명령어 리스트를 내용으로 가진, 디스크에 저장된 파일과 같은 수동적인 존재이다.
그러나 프로세스는 다음에 실행할 명령어를 지정하는 프로그램 카운터와 관련 자원의 집합을 가진 능동적인 존재이다.
실행 파일이 메모리에 적재될 때 프로그램은 프로세스가 된다. 실행 파일을 메모리에 적재하는 일반적인 두 가지 방식은, 실행 파일을 나타내는 아이콘을 더블 클릭하는 방식과 명령어 라인 상에서 파일 이름을 입력하는 방식이다.
두 프로세스들이 동일한 프로그램에 연관될 수 있지만, 이들은 두 개의 별도의 실행 순서로 간주된다.
텍스트 섹션이 동등하다 할지라도 데이터, 힙 및 스택 섹션은 다를 수 있다.
프로세스 자체가 다른 개체를 위한 실행 환경으로 동작할 수도 있다. 예를 들면 Java 프로그래밍 환경이 있다.
대부분의 상황에서 실행 가능한 Java 프로그램은 JVM 안에서 실행된다. JVM은 적재된 Java 코드를 해석하고 그 코드를 대신하여 원 기계어를 이용하여 행동을 취하는 프로세스로서 프로그램을 실행한다.
3.1.2. 프로세스 상태
프로세스는 실행되면서 그 상태가 변한다. 프로세스의 상태는 부분적으로 그 프로세스의 현재의 활동에 따라 정의된다.
프로세스는 다음 상태 중 하나에 있게 된다.
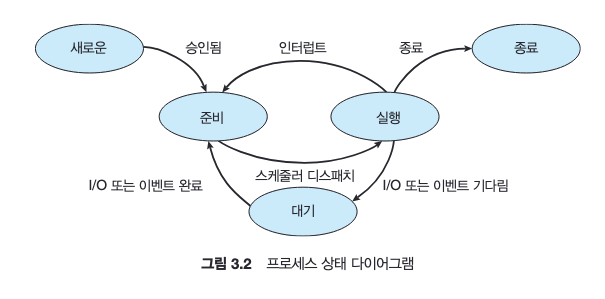
- new: 프로세스가 생성되었다.
- running: 명령어들이 실행되고 있다.
- waiting: 프로세스가 어떤 이벤트가 일어나기를 기다린다.
- ready: 프로세스가 처리기에 할당되기를 기다린다.
- terminated: 프로세스의 실행이 종료되었다.
3.1.3. 프로세스 제어 블록
각 프로세스는 운영체제에서 PCB(Process Control Block)에 의해 표현된다.
프로세스 제어 블록은 특정 프로세스와 연관된 여러 정보를 수록하며, 다음과 같은 것들을 포함한다.
- 프로세스 상태 (new, ready, running, waiting, halted 등)
- 프로그램 카운터: 이 프로세스가 다음에 실행할 명령어의 주소
- CPU 레지스터들: 누산기, 인덱스 레지스터, 스택 레지스터, 범용 레지스터들과 상태 코드 정보가 포함된다. 프로그램 카운터와 함께 이 상태 정보는 나중에 프로세스가 다시 스케줄될 때 계속 올바르게 실행되도록 하기 위해서 인터럽트 발생 시 저장되어야 한다. 컴퓨터 구조에 따라 다양한 수와 유형을 가진다.
- CPU 스케줄링 정보: 프로세스 우선순위, 스케줄 큐에 대한 포인터와 다른 스케줄 매개변수를 포함한다.
- 메모리 관리 정보: 운영체제에 의해 사용되는 메모리 시스템에 따라 기준 레지스터와 한계 레지스터의 값, 운영체제가 사용하는 메모리 시스템에 따라 페이지 테이블 또는 세그먼트 테이블 등과 같은 정보를 포함한다.
- 회계 정보: CPU 사용 시간과 경과된 실시간, 시간 제한, 계정 번호, 잡 또는 프로세스 번호 등을 포함한다.
- 입출력 상태 정보: 이 프로세스에 할당된 입출력 장치들과 열린 파일의 목록 등을 포함한다.
3.1.4. 스레드
이제까지 논의한 프로세스 모델은 프로세스가 단일의 실행 스레드를 실행하는 프로그램임을 암시했다.
이 단일 제어 스레드는 프로세스가 한 번에 한 가지 일만 실행하도록 허용한다. 따라서 사용자는 문자를 입력하면서 동시에 철자 검사기를 실행할 수 없다.
대부분의 현대 운영체제는 프로세스 개념을 확장하여 한 프로세스가 다수의 실행 스레드를 가질 수 있도록 허용하며, 여러 스레드가 병렬로 실행될 수 있다.
스레드를 지원하는 시스템에서 PCB는 각 스레드에 관한 정보를 포함하도록 확장된다.
3.2. 스케줄링
다중 프로그래밍의 목적은 CPU 이용을 최대화하기 위하여 항상 어떤 프로세스가 실행되도록 하는 데 있다.
시분할의 목적은 각 프로그램이 실행되는 동안 사용자가 상호 작용할 수 있도록 프로세스들 사이에서 CPU 코어를 빈번하게 교체하는 것이다.
이 목적을 달성하기 위해 프로세스 스케줄러는 코어에서 실행 가능한 여러 프로세스 중에서 하나의 프로세스를 선택한다. 각 CPU 코어는 한 번에 하나의 프로세스를 실행할 수 있다.
단일 CPU 코어가 있는 시스템의 경우 한 번에 2개 이상의 프로세스가 실행될 수 없지만, 다중 코어 시스템은 한 번에 여러 프로세스를 실행할 수 있다.
코어보다 많은 프로세스가 있는 경우 초과 프로세스는 코어가 사용 가능해지고 다시 스케줄될 때까지 기다려야 한다.
현재 메모리에 있는 프로세스의 수를 다중 프로그래밍 정도라고 한다.
다중 프로그래밍 및 시간 공유의 목표를 균형있게 유지하려면 프로세스의 일반적인 동작을 고려해야 한다.
일반적으로 대부분의 프로세스는 I/O 바운드 또는 CPU 바운드로 설명할 수 있다.
- I/O 바운드 프로세스는 계산에 소비하는 것보다 I/O에 더 많은 시간을 소비하는 프로세스
- CPU 바운드 프로세스는 계산에 더 많은 시간을 사용하여 I/O 요청을 자주 생성하지 않음
3.2.1. 스케줄링 큐
프로세스가 시스템에 들어가면 준비 큐에 들어가서 준비 상태가 되어 CPU 코어에서 실행되기를 기다린다.
이 큐는 일반적으로 연결리스트로 저장된다. 준비 큐 헤더에는 리스트의 첫 번째 PCB에 대한 포인터가 저장되고 각 PCB에는 준비 큐의 다음 PCB를 가리키는 포인터 필드가 포함된다.
프로세스에 CPU 코어가 할당되면 프로세스는 잠시 동안 실행되어 결국 종료되거나, 인터럽트 되거나 혹은 I/O 요청의 완료와 같은 특정 이벤트가 발생할 때까지 기다린다.
프로세스가 디스크와 같은 장치에 I/O 요청을 한다고 가정하자. 장치는 프로세서보다 상당히 ㅈ느리게 실행되므로 프로세스는 I/O가 사용 가능할 때까지 기다려야 한다.
I/O 완료와 같은 특정 이벤트가 발생하기를 기다리는 프로세스는 대기 큐에 삽입된다.
프로세스 스케줄링의 일반적인 표현은 큐잉 다이어그램이다.

- 두 가지 유형의 큐(준비 큐, 대기 큐의 집합)가 제시되어 있다.
- 원은 큐에 서비스를 제공하는 자원을 나타내고 화살표는 시스템의 프로세스의 흐름을 나타낸다.
- 새 프로세스는 처음에 준비 큐에 놓이며, 실행을 위해 선택되거나 또는 디스패치될 때까지 기다린다.
- 프로세스에 CPU 코어가 할당되고 실행 상태가 되면, 여러 이벤트 중 하나가 발생할 수 있다.
- 프로세스가 I/O 요청을 공표한 다음 I/O 대기 큐에 놓일 수 있다.
- 프로세스는 새 자식 프로세스를 만든 다음 자식의 종료를 기다리는 동안 대기 큐에 놓일 수 있다.
- 인터럽트 또는 타임 슬라이스가 만료되어 프로세스가 코어에서 강제로 제거되어 준비 큐로 들어갈 수 있다.
- 처음 두 경우에는 프로세스가 결곡 대기 상태에서 준비 상태로 전환된 다음 준비 큐에 다시 들어간다.
- 프로세스는 종료될 때까지 이 주기를 계속하며, 종료 시점에 모든 큐에서 제거되고 PCB 및 자원이 반환된다.
3.2.2. CPU 스케줄링
프로세스는 수명 주기 동안 준비 큐와 다양한 대기 큐를 이주한다.
CPU 스케줄러의 역할은, 준비 큐에 있는 프로세스 중에서 선택된 하나의 프로세스에 CPU 코어를 할당하는 것이다.
CPU 스케줄러는 CPU를 할당하기 위한 새 프로세스를 자주 선택해야 한다.
I/O 바운드 프로세스는 I/O 요청을 대기하기 전에 몇 밀리초 동안만 실행할 수 있다.
CPU 바운드 프로세스에는 오랜 시간 동안 CPU 코어가 필요하지만 스케줄러는 프로세스에게 코어를 장기간 부여할 가능성이 없다.
대신 프로세스에서 CPU를 강제로 제거하고 실행될 다른 프로세스를 스케줄하도록 설계될 가능성이 높다.
일부 운영체제는 스와핑으로 알려진 중간 형태의 스케줄링을 가지고 있는데, 핵심 아이디어는 때로는 메모리에서 프로세스를 제거하여 다중 프로그래밍의 정도를 감소시키는 것이 유리할 수 있다는 것이다.
나중에 프로세스를 메모리에 다시 적재할 수 있으며, 중단된 위치에서 실행을 계속할 수 있다.
프로세스를 메모리에서 디스크로 스왑아웃하고 현재 상태를 저장한 후, 이후 디스크에서 메모리로 스왑인하여 상태를 복원할 수 있기 때문에 이 기법을 스와핑이라고 한다.
스와핑은 일반적으로 메모리가 초과 사용되어 가용공간을 확보해야 할 때만 필요하다.
3.2.3. 문맥 교환 (Context Switch)
인터럽트는 CPU 코어를 현재 작업에서 뺏어내어 커널 루틴을 실행할 수 있게 한다. 이러한 연산은 범용 시스템에서 자주 발생한다.
인터럽트가 발생하면 시스템은 인터럽트 처리가 끝난 후에 문맥을 복구할 수 있도록 현재 실행 중인 프로세스의 현재 문맥을 저장할 필요가 있다.
문맥은 프로세스의 PCB에 표현되며, 문맥은 CPU 레지스터의 값, 프로세스의 상태, 메모리 관리 정보 등을 포함한다.
일반적으로 커널 모드이건 사용자 모드이건 CPU의 현재 상태를 저장하는 작업을 수행하고, 나중에 연산을 재개하기 위하여 상태 복구 작업을 수행한다.
CPU 코어를 다른 프로세스로 교환하려면 이전의 프로세스의 상태를 보관하고 새로운 프로세스의 보관된 상태를 복구하는 작업이 필요하다.
이 작업을 문맥 교환(Context Switch)이라 한다.
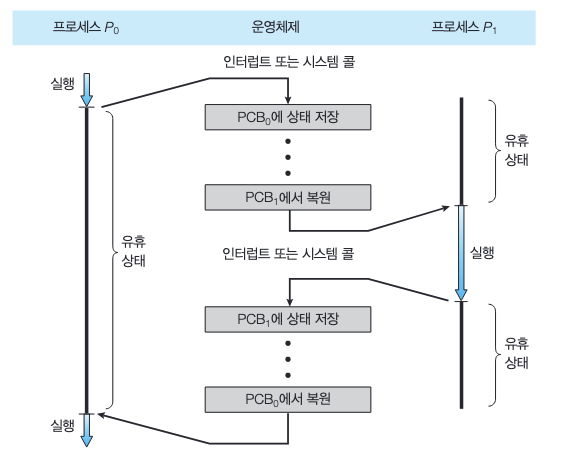
- 문맥 교환이 일어나면, 커널은 과거 프로세스의 문맥을 PCB에 저장하고, 실행이 스케줄된 새로운 프로세스의 저장된 문맥을 복구한다.
- 문맥 교환이 진행될 동안 시스템이 아무런 일을 하지 못하므로, 문맥 교환 시간은 순수한 오버헤드이다.
- 교환 속도는 메모리의 속도, 반드시 복사되어야 하는 레지스터의 수, 특수 명령어의 존재에 좌우되므로 기계에 따라 다르다.
문맥 교환 시간은 하드웨어의 지원에 크게 좌우된다. 또한 운영체제가 복잡할수록, 문맥 교환 시 해야 할 작업의 양이 더 많아진다.
문맥 교환 시 현재 프로세스의 주소 공간은 다음 태스크의 공간이 사용 준비되는 동안 반드시 보존되어야 한다.
주소 공간이 어떤 식으로 보존되고, 보존하기 위해 수행해야 할 작업의 양은 운영체제의 메모리 관리 기법에 따라 달라진다.
3.3. 프로세스에 대한 연산
대부분 시스템 내의 프로세스들은 병행 실행될 수 있으며, 반드시 동적으로 생성되고, 제거되어야 한다. 그러므로 운영체제는 프로세스 생성 및 종료를 위한 기법을 제공해야 한다.
3.3.1. 프로세스 생성
프로세스는 실행되는 동안 여러 개의 새로운 프로세스들을 생성할 수 있다.
생성하는 프로세스를 부모 프로세스라고 부르고, 새로운 프로세스는 자식 프로세스라고 부른다.
이 새로운 프로세스들은 각각 다시 다른 프로세스들을 생성할 수 있으며, 그 결과 프로세스의 트리를 형성한다.
대부분의 현대 운영체제들은 유일한 프로세스 식별자(PID)를 사용하여 프로세스를 구분하며, 보통 정수 값을 가진다.
PID는 시스템의 각 프로세스에 고유한 값을 가지도록 할당되며, 이 식별자를 통하여 커널이 유지하고 있는 프로세스의 다양한 속성에 접근하기 위한 인덱스로 사용된다.
그림은 Linux 운영체제의 전형적인 프로세스 트리를 보여준다.
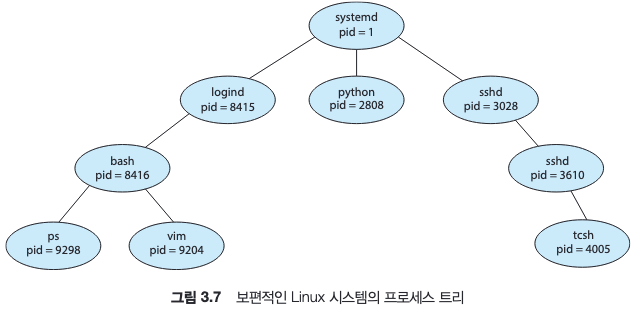
- PID가 1인
systemd프로세스는 시스템이 부트될 때 생성되는 첫 번째 사용자 프로세스이며, 모든 사용자 프로세스의 루트 부모 프로세스 역할을 수행한다. systemd의 두 자식 프로세스logind와sshd프로세스가 있다.logind프로세스는 시스템에 직접 로그인하는 클라이언트를 관리하는 책임을 지며,sshd프로세스는ssh를 사용하여 시스템에 접속하는 클라이언트의 관리를 책임진다.- 사용자는 bash 셸을 사용하고 있으며, 로그인 후
ps프로세스와vim편집기 프로세스를 생성하였다.
UNIX 시스템과 Linux 시스템에서는 ps 명령어를 이용하여 프로세스들의 목록을 얻을 수 있다.
일반적으로 프로세스가 자식 프로세스를 생성할 때, 그 자식 프로세스는 자신의 임무를 달성하기 위하여 어떤 자원이 필요하다.
자식 프로세스는 이 자원을 운영체제로부터 직업 얻거나, 부모 프로세스가 가진 자원의 부분 집합만을 사용하도록 제한될 수 있다.
부모 프로세스는 자원을 분할하여 자식 프로세스들에게 나누어주거나 메모리나 파일과 같은 몇몇 자원들은 자식 프로세스들이 같이 사용하게 할 수도 있다.
부모 프로세스 자원의 일부만을 사용하도록 자식 프로세스가 쓸 수 있게 제한하며, 자식 프로세스들을 많이 생성하여 시스템을 과부하 상태로 만드는 프로세스를 방지할 수 있다.
물리적, 논리적 자원을 제공하는 것 외에 부모 프로세스는 자식 프로세스에 초기화 데이터를 전달할 수 있다.
hw1.c라는 파일의 내용을 단말기의 화면에 나타내는 기능을 하는 프로세스를 생각해보자.
- 이 프로세스가 생성될 때 부모 프로세스로부터 입력 데이터로 hw1.c라는 파일 이름을 얻을 수 있다. 이 파일 이름을 사용하여 파일을 열고 내용을 출력한다.
- 혹은 출력 장치의 이름도 전달받을 수 있을 것이다.
- 대체 방안으로, 어떤 운영체제는 자식 프로세스에 자원을 전달한다. 이와 같은 시스템에서는, 새로운 프로세스는 hw1.c와 터미널 장치에 해당하는 두 개의 열린 파일을 전달받고 단순히 두 장치 사이에서 데이터를 전송하는 작업만 하면 된다.
프로세스가 새로운 프로세스를 생성할 때, 두 프로세스를 실행시키는 두 가지 방법이 존재한다.
- 부모는 자식과 병행하게 실행을 계속한다.
- 부모는 일부 또는 모든 자식이 실행을 종료할 때까지 기다린다.
새로운 프로세스들의 주소 공간 측면에서 볼 때 다음과 같은 두 가지 가능성이 있다.
- 자식 프로세스는 부모 프로세스의 복사본이다.
- 자식 프로세스는 자신에게 적재될 새로운 프로그램을 가지고 있다.
UNIX 운영체제에서 각 프로세스는 프로세스 식별자로 확인되며, 유일한 정수이다.
새로운 프로세스는 fork 시스템 콜로 생성되며, 원래 프로세스의 주소 공간의 복사본으로 구성된다. 이 기법은 부모 프로세스가 자식 프로세스와 쉽게 통신할 수 있게 한다.
두 개의 프로세스들은 fork 후의 명령어에서부터 실행을 계속하며, 이때 한 가지 다른 점은 fork의 복귀 코드가 서로 다르다는 것이다.
부모 프로세스는 자식 프로세스의 식별자를 받는 데 반해, 새로운 프로세스는 0을 받는다.
fork 시스템 콜 다음 두 프로세스 중 한 프로세스가 exec 시스템 콜을 사용하여 자신의 메모리 공간을 새로운 프로그램으로 교체한다.
exec 시스템 콜은 이진 파일을 메모리로 적재하고 그 프로그램의 실행을 시작한다. 이때 원래 프로그램의 메모리 이미지는 파괴된다.
이와 같은 방법으로 두 프로세스는 통신할 수 있으며, 각자 갈 길을 간다.
이후 부모는 더 많은 자식을 생성할 수 있으며, 또는 자식이 실행되는 동안 할 일이 없으면 자식이 종료될 때까지 준비 큐에서 자신을 제거하기 위해 wait 시스템 콜을 호출한다.
exec을 호출하면 프로세스의 주소 공간을 새 프로그램으로 덮어쓰기 때문에 exec 시스템 콜은 오류가 발생하지 않는 한 제어를 반환하지 않는다.
아래 C 프로그램은 앞에서 설명한 UNIX 시스템 콜을 보여준다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
#include <sys/types.h>
#include <stdio.h>
#include <unistd.h>
int main() {
pid_t pid;
// 새 프로세스 생성
pid = fork();
if (pid < 0) {
// 오류 발생
fprintf(stderr, "Fork Failed");
return 1;
}
else if (pid == 0) {
// PID = 0 -> 자식 프로세스
execlp("/bin/ls", "ls", NULL);
}
else {
// PID != 0 -> 부모 프로세스
wait(NULL);
printf("Child Complete");
}
return 0;
}
- 동일한 프로그램의 복사본을 실행하는 두 개의 서로 다른 프로세스를 갖는다.
- 유일한 차이점은 자식 프로세스에 보이는
pid값은 0이고, 부모 프로세스에게 보이는pid값은 0보다 큰 정수값이다. - 자식 프로세스는 열린 파일과 같은 자원뿐만 아니라, 특권과 스케줄링 속성을 부모 프로세스로부터 상속받는다. 그런 후
execlp시스템 콜을 사용하여 자신의 주소 공간을 UNIX 명령/bin/ls로 덮어쓴다. - 부모 프로세스는
wait시스템 콜로 자식 프로세스가 끝나기를 기다린다. 자식 프로세스가 끝나면wait호출로부터 재개하여,exit시스템 콜을 사용하여 끝낸다.
다른 예로 Windows에서의 프로세스 생성에 대해 고려한다.
프로세스는 Windows API의 CreateProcess 함수를 이용하여 생성되는데, 이 함수는 부모 프로세스가 새로운 자식 프로세스를 생성한다는 점에서 fork와 유사하다.
그러나 fork가 부모 프로세스로부터 주소 공간을 상속받는 자식 프로세스를 생성하는 반면, CreateProcess는 자식 프로세스가 생성될 때 주소 공간에 명시된 프로그램을 적재한다.
또한, fork에는 아무런 인자도 전달되지 않는 반면 CreateProcess는 10개 이상의 매개변수를 요구한다.
아래 C 프로그램은 mspaint.exe를 적재하는 자식 프로세스를 생성하는 CreateProcess를 보여준다.
#include <Windows.h>
#include <stdio.h>
int main(void) {
STARTUPINFO si;
PROCESS_INFORMATION pi;
ZeroMemory(&si, sizeof(STARTUPINFO));
si.cb = sizeof(STARTUPINFO);
ZeroMemory(&pi, sizeof(PROCESS_INFORMATION));
if (CreateProcess(
NULL,
"C:\\WINDOWS\\System32\\mspaint.exe",
NULL,
NULL,
FALSE,
0,
NULL,
NULL,
&si,
&pi
)) {
fprintf(stderr, "CreateProcess Failed");
return -1;
}
WaitForSingleObject(pi.hProcess, INFINITE);
printf("Child Complete");
CloseHandle(pi.hProcess);
CloseHandle(pi.hThread);
}
- 마지막 두 개의 매개변수는
STARTUPINFO와PROCESS_INFORMATION구조체 인스턴스이다.STARTUPINFO는 윈도 크기와 모양, 표준 입력과 출력 파일에 대한 핸들과 같은 새로운 프로세스의 특성을 지정한다.PROCESS_INFORMATION구조체는 새로 생성된 프로세스와 스레드에 대한 핸들과 식별자들을 포함한다.
- 첫 두 개의 변수는 응용 프로그램의 이름과 명령어 라인 매개변수이다.
- 응용 프로그램의 이름이 NULL이면 명령어 라인 매개변수가 적재할 응용 프로그램을 지정한다.
- 여기서는 mspaint.exe를 적재하게 된다.
- 이후의 매개변수에 대해서는 기본 값을 사용하여 프로세스와 스레드 핸들을 상속받고 생성 플래그가 없다고 명시한다.
- 부모 프로세스의 기존 환경 블록을 사용하고 시작 디렉터리로 부모의 시작 디렉터리를 사용한다.
- 부모 프로세스는
WaitForSingleObject를 호출해 자식 프로세스가 끝나기를 기다린다. 이 함수는 자식 프로세스의 핸들을 전달받는다.
3.3.2. 프로세스 종료
프로세스가 마지막 문장의 실행이 끝나고 exit 시스템 콜을 사용하여 운영체제에 자신의 삭제를 요청하면 종료한다.
이 시점에서 프로세스는 자신을 기다리고 있는 부모 프로세스에 상태 값을 반환할 수 있다.
물리 메모리와 가상 메모리, 열린 파일, 입출력 버퍼를 포함한 프로세스의 모든 자원이 할당 해제되고 운영체제로 반납된다.
프로세스 종료가 발생하는 다른 경우는, 다른 프로세스에 의해 종료가 유발되는 경우이다. (Windows의 TerminateProcess 등) 통상적으로 이런 시스템 콜은 종료될 프로세스의 부모만이 호출할 수 있다.
부모가 자식을 종료시키려면 자식의 pid를 알아야 한다. 그러므로 한 프로세스가 새로운 프로세스를 만들 때, 새로 만들어진 프로세스의 PID가 부모에게 전달된다.
부모는 여러 이유로 자식 중 하나의 실행을 종료할 수 있다.
- 자식이 자신에게 할당된 자원을 초과하여 사용하는 경우
- 자식에게 할당된 태스크가 더 이상 필요 없을 때
- 부모가 exit를 하는데, 운영체제는 부모가 exit한 후에 자식이 실행을 계속하는 것을 허용하지 않는 경우
몇몇 시스템에서는 부모 프로세스가 종료한 이후에 자식 프로세스가 존재할 수 없다.
이런 시스템에서는 프로세스가 종료되면 그로부터 비롯된 모든 자식 프로세스들도 종료되어야 한다. 이것을 연쇄식 종료(cascading termination)라고 하며, 운영체제가 시행한다.
프로세스 실행과 종료를 설명하기 위해 Linux와 UNIX 시스템에서 exit 시스템 콜을 사용하여 프로세스를 종료시키는 것을 고려해보자.
exit시스템 콜은 종료 상태를 나타내는 인자를 전달받는다.- 정상적인 종료에서
exit는 직접적으로 호출되거나, C 런타임 라이브러리가 기본으로exit호출을 추가하므로 간접적으로 호출될 수 있다. - 부모 프로세스는
wait시스템 콜을 사용해서 자식 프로세스가 종료할 때를 기다릴 수 있다. wait시스템 콜은 부모가 자식의 종료 상태를 얻어낼 수 있도록 하나의 인자를 전달받으며, 어느 자식이 종료되었는지 구별할 수 있도록 종료된 자식의 PID를 반환한다.
프로세스가 종료하면 사용하던 자원은 운영체제에게 반환된다.
그러나 프로세스의 종료 상태가 저장되는 프로세스 테이블의 해당 항목은 부모 프로세스가 wait을 호출할 때까지 남아 있게 된다.
종료되었지만 부모 프로세스가 아직 wait 호출을 하지 않은 프로세스를 좀비 프로세스라고 한다.
종료하게 되면 모든 프로세스는 좀비 상태가 되지만 아주 짧은 시간만 머무르며, 부모가 wait을 호출하면 좀비 프로세스의 프로세스 식별자와 프로세스 테이블의 해당 항목이 운영체제에 반환된다.
부모 프로세스가 wait을 호출하는 대신 종료한다면, 이 상황에서 자식 프로세스는 고아 프로세스가 된다.
전통적인 UNIX는 고아 프로세스의 새로운 부모 프로세스로 init 프로세스를 지정함으로써 이 문제를 해결한다.
init 프로세스는 주기적으로 wait을 호출하여 고아 프로세스의 종료 상태를 수집하고 프로세스 식별자와 프로세스 테이블 항목을 반환한다.
대부분의 Linux 시스템은 init을 systemd로 대체했다. systemd 역시 동일한 역할을 수행할 수 있지만 Linux는 systemd 이외의 프로세스가 고아 프로세스를 상속하고 종료를 관리하도록 허용한다.
3.3.2.1. Android 프로세스 계층
모바일 운영체제는 제한된 메모리와 같은 자원 제약 때문에, 시스템 자원을 회수하기 위해 기존 프로세스르 종료해야 할 수도 있다.
Android는 임의의 프로세스를 종료하지 않고 프로세스의 중요도 계층을 식별하며, 시스템이 프로세스를 종료하여 새로운 또는 보다 중요한 프로세스를 위한 자원을 확보해야 할 경우 중요도가 낮은 프로세스부터 종료한다.
가장 중요한 순서부터 프로세스를 분류하면 다음과 같다.
- 전경 프로세스(foreground process): 사용자가 현재 상호 작용하고 있는 응용 프로그램을 나타내며, 화면에 보이는 현재 프로세스
- 가시적 프로세스(visible process): 전경에서 직접 볼 수 없지만 전경 프로세스가 참조하는 활동(즉, 현재 상태가 전경 프로세스에 표시되는 활동을 수행하는 프로세스)을 수행하는 프로세스
- 서비스 프로세스: 백그라운드 프로세스와 유사하지만 사용자가 인지할 수 있는 활동(음악 스트리밍 등)을 수행하는 프로세스
- 백그라운드 프로세스: 활동을 수행하고 있지만 사용자가 인식하지 못하는 프로세스
- 빈 프로세스: 응용 프로그램과 관련된 활성 구성요소가 없는 프로세스
시스템 자원을 회수해야 하는 경우 Android는 먼저 빈 프로세스를 종료한 다음 백그라운드 프로세스 등의 순서로 종료한다.
프로세스에는 중요도 순위가 지정되고 Android는 프로세스에 가능한 높은 순위를 지정하려고 한다. 예를 들어, 프로세스가 서비스를 제공하고 있고 가시적이면 더 중요한 가시적 분류가 지정된다.
Android 개발 관행은 프로세스 수명주기 지침을 따르는 것을 권장한다.
이 지침을 준수하면 프로세스 상태는 종료 전에 저장되고 사용자가 응용 프로그램으로 다시 전환하면 저장된 상태에서부터 재개된다.
3.4. 프로세스 간 통신
운영체제 내에서 실행되는 병행 프로세스들은 독립적이거나 협력적인 프로세스들일 수 있다.
- 프로세스가 시스템에서 실행 중인 다른 프로세스들과 데이터를 공유하지 않는 프로세스들은 독립적
- 프로세스가 시스템에서 실행 중인 다른 프로세스들에 영향을 주거나 받으면 프로세스들은 협력적
프로세스 협력을 허용하는 환경을 제공하는 데는 몇 가지 이유가 있다.
- 정보 공유: 여러 응용 프로그램이 동일한 정보에 흥미를 느낄 수 있으므로, 그러한 정보를 병행적으로 접근할 수 있는 환경을 제공해야 한다.
- 계산 가속화: 특정 태스크를 빨리 실행하고자 한다면, 그것을 서브태스크로 나누어 이들 각각이 다른 서브태스크들과 병렬로 실행되게 해야 한다. 이러한 가속화는 복수 개의 처리 코어를 가진 경우에만 달성할 수 있다.
- 모듈성: 시스템 기능을 별도의 프로세스들 또는 스레드들로 나누어, 모듈식 형태로 시스템을 구성하기를 원할 수도 있다.
협력적 프로세스들은 데이터를 교환할 수 있는, 즉 서로 데이터를 보내거나 받을 수 있는 프로세스 간 통신(IPC; Inter-Process Communication) 기법이 필요하다.
프로세스 간 통신에는 기본적으로 공유 메모리와 메시지 전달의 두 가지 모델이 있다.
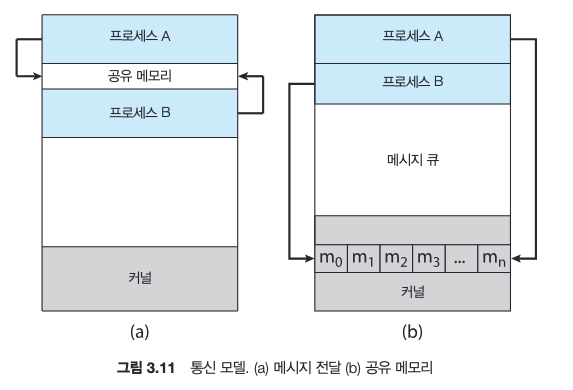
- 공유 메모리 모델: 협력 프로세스들에 의해 공유되는 메모리의 영역이 구축된다. 프로세스들은 그 영역에 데이터를 읽고 씀으로써 정보를 교환한다.
- 메시지 전달 모델: 통신이 협력 프로세스들 사이에 교환되는 메시지를 통하여 이루어진다.
두 모델은 운영체제에서 통상적이며 많은 시스템이 두 가지를 모두 구현한다.
메시지 전달 모델은 충돌을 회피할 필요가 없으므로 적은 양의 데이터를 교환하는 데 유용하며, 분산 시스템에서 공유 메모리보다 구현하기 쉽다.
메시지 전달 모델은 통상 시스템 콜을 사용하여 구현되므로 커널 간섭 등의 부가적인 시간 소비 작업이 필요하다. 따라서 공유 메모리 모델이 메시지 전달보다 더 빠르다.
공유 메모리 시스템에서는 공유 메모리 영역을 구축할 때만 시스템 콜이 필요하다. 공유 메모리 영역이 구축되면 모든 접근은 일반적인 메모리 접근으로 취급되어 커널의 도움이 필요 없다.
3.5. 공유 메모리 시스템에서의 프로세스 간 통신
공유 메모리를 사용하는 프로세스 간 통신에서는 통신하는 프로세스들이 공유 메모리 영역을 구축해야 한다.
통상 공유 메모리 영역은 공유 메모리 세그먼트를 생성하는 프로세스의 주소 공간에 위치한다.
이 공유 메모리 세그먼트를 이용하여 통신하고자 하는 다른 프로세스들은 이 세그먼트를 자신의 주소 공간에 추가하여야 한다.
일반적으로 운영체제는 한 프로세스가 다른 프로세스의 메모리에 접근하는 것을 금지한다.
공유 메모리는 둘 이상의 프로세스가 이 제약 조건을 제거하는 것에 동의하는 것을 필요로 한다. 그런 후에 프로세스들은 공유 영역에 읽고 씀으로써 정보를 교환할 수 있다.
데이터의 형식과 위치는 이들의 프로세스에 의해 결정되며 운영체제의 소관이 아니다. 또한 프로세스들은 동시에 동일한 위치에 쓰지 않도록 책임져야 한다.
생산자-소비자 문제에서 생산자 프로세스는 정보를 생산하고 소비자 프로세스는 정보를 소비한다.
하나의 해결책은 공유 메모리를 사용하는 것이다.
생산자와 소비자 프로세스들이 병행으로 실행되도록 하려면, 생산자가 정보를 채워 넣고 소비자가 소모할 수 있는 항목들의 버퍼가 반드시 사용 가능해야 한다.
이 버퍼는 생산자와 소비자가 공유하는 메모리 영역에 존재하게 되며, 생산자가 한 항목을 생성하고, 그동안에 소비자는 다른 항목을 소비할 수 있다.
생산자와 소비자가 반드시 동기화되어야 생산되지도 않은 항목들을 소비자가 소비하려고 시도하지 않을 것이다.
두 가지 유형의 버퍼가 사용된다. 무한 버퍼(unbounded buffer)의 생산자 소비자 문제에서는 버퍼의 크기에 실질적인 한계가 없다. 소비자는 새로운 항목을 기다려야 할 수도 있지만, 생산자는 항상 새로운 항목을 생성할 수 있다.
유한 버퍼(bounded buffer)는 버퍼의 크기가 고정되어 있다고 가정한다. 이 경우 버퍼가 비어 있으면 소비자는 반드시 대기해야 하며, 모든 버퍼가 채워져 있으면 생산자가 대기해야 한다.
3.6. 메시지 전달 시스템에서의 프로세스 간 통신
메시지 전달 방식은 동일한 주소 공간을 공유하지 않고도 프로세스들이 통신하고, 그들의 동작을 동기화할 수 있도록 허용하는 기법을 제공한다.
메시지 전달 방식은 통신하는 프로세스들이 네트워크에 의해 연결된 다른 컴퓨터들에 존재할 수 있는 분산 환경에서 특히 유용하다.
메시지 전달 시스템은 최소한 두 가지 연산을 제공한다.
send(message)receive(message)
프로세스가 보낸 메시지는 고정 길이일 수도 있고 가변 길이일 수도 있다.
고정 길이 메시지만 보낼 수 있다면 시스템 수준의 구현은 직선적이다. 하지만 이러한 제한은 프로그래밍 작업을 더욱 힘들게 한다.
가변 길이 메시지는 보다 복잡한 시스템 수준의 구현이 있어야 하지만, 프로그래밍 작업은 더 간단해진다.
만약 프로세스 P와 Q가 통신을 원하면, 반드시 서로 메시지를 보내고 받아야 한다. 이들 사이에 통신 연결이 설정되어야 한다.
이 연결은 다양한 방법으로 구현할 수 있으며, 하나의 send와 receive 연산을 논리적으로 구현하는 방법은 다음과 같다.
- 직접 또는 간접 통신
- 동기식 또는 비동기식 통신
- 자동 또는 명시적 버퍼링
3.6.1. 명명(Naming)
통신을 원하는 프로세스들은 서로를 가리킬 방법이 있어야 한다. 이들은 간접 통신 또는 직접 통신을 사용할 수 있다.
직접 통신 하에서, 통신을 원하는 각 프로세스는 통신의 수신자 또는 송신자의 이름을 명시해야 한다.
send(P, message): 프로세스 P에 메시지를 전송receive(Q, message): 프로세스 Q로부터 메시지 수신
이 기법에서 통신 연결은 다음의 특성을 가진다.
- 통신을 원하는 각 프로세스의 쌍들 사이에 연결이 자동으로 구축된다. 프로세스들은 통신하기 위해 상대방의 신원만 알면 된다.
- 연결은 정확히 두 프로세스 사이에만 연관된다.
- 통신하는 프로세스들의 각 쌍 사이에는 정확하게 하나의 연결이 존재해야 한다.
이 기법은 주소 방식에서 대칭성을 보인다. 즉, 송신자와 수신자 프로세스가 모두 통신하려면 상대방의 이름을 제시해야 한다.
이 기법의 변형으로서 주소 지정 시에 비대칭을 사용할 수도 있다. 송신자만 수신자 이름을 지명하며, 수신자는 송신자의 이름을 제시할 필요가 없다.
send(P, message): 프로세스 P에 메시지를 전송receive(id, message): 임의 프로세스로부터 메시지를 수신한다. 변수id는 통신을 발생시킨 프로세스의 이름으로 설정된다.
이들 기법 모두 프로세스를 지정하는 방식 때문에 모듈성을 제한한다는 것이 단점이다. 프로세스의 이름을 바꾸면 모든 다른 프로세스 지정 부분을 검사할 필요가 있다.
일반적으로 이러한 하드 코딩 기법은, 이 상황에서는 신원을 명시적으로 표현해야 한다.
간접 통신에서 메시지들은 메일박스 또는 포트로 송신되고, 그것으로부터 수신된다.
메일박스는 추상적으로 프로세스들에 의해 메시지들이 넣어지고, 메시지들이 제거될 수 있는 객체로도 볼 수 있다.
각 메일박스는 고유의 id를 가진다. 예를 들어 POSIX 메시지 큐는 메일박스를 식별하기 위해 정수 값을 사용한다.
이 기법에서 프로세스는 다수의 상이한 메일박스를 통해 다른 프로세스들과 통신할 수 있다.
두 프로세스들이 공유 메일박스를 가질 때만 이들 프로세스가 통신할 수 있다.
send(A, message): 메시지를 메일박스 A로 송신한다.receive(A, message): 메시지를 메일박스 A로부터 수신한다.
이 방법에서 통신 연결은 다음 특성을 가진다.
- 한 쌍의 프로세스들 사이의 연결은 이들 프로세스가 공유 메일박스를 가질 때만 구축된다.
- 연결은 두 개 이상의 프로세스들과 연관될 수 있다.
- 통신하고 있는 각 프로세스 사이에는 다수의 서로 다른 연결이 존재할 수 있고, 각 연결은 하나의 메일박스에 대응된다.
세 프로세스 A,B,C가 모두 메일박스 M을 공유한다고 가정하자. 프로세스 A는 메시지를 M에 송신하고, B와 C는 각각 M으로부터 receive를 실행한다. 어느 프로세스가 A가 보낸 메시지를 수신할까? 이 문제에 대한 답은 우리가 선택할 기법에 좌우된다.
- 하나의 링크는 최대 두 개의 프로세스와 연관되도록 허용한다.
- 한순간에 최대 하나의 프로세스가
receive연산을 실행하도록 허용한다. - 어느 프로세스가 메시지를 수신할 것인지 시스템이 임의로 선택하도록 한다.
메일박스는 한 프로세스 또는 운영체제에 의해 소유될 수 있다.
메일박스가 한 프로세스에 의해 소유된다면, 우리는 소유자와 메일박스의 사용자를 구분할 수 있다. 각 메일박스가 고유한 소유자를 가지고 있기 때문에, 이 메일박스로 보내진 메시지를 어느 프로세스가 수신할 지에 대한 혼란이 있을 수 없다.
메일박스를 소유하고 있는 프로세스가 종료할 때, 메일박스는 사라진다. 그 후에 이 메일박스로 메시지를 송신하는 모든 프로세스는 더는 메일박스가 존재하지 않는다는 사실을 반드시 통보받아야 한다.
반면, 운영체제가 소유한 메일박스는 자체적으로 존재한다. 이것은 독립적인 것으로 어떤 특정 프로세스에 예속되지 않는다.
운영체제는 한 프로세스에 다음을 할 수 있도록 허용하는 기법을 반드시 제공해야 한다.
- 새로운 메일박스를 생성한다.
- 메일박스를 통해 메시지를 송신하고 수신한다.
- 메일박스를 삭제한다.
새로운 메일박스를 생성하는 프로세스는 디폴트로 메일박스의 소유자가 된다.
초기에는 소유자만이 이 메일박스를 통해 메시지를 수신할 수 있는 유일한 프로세스이다. 그러나 소유권과 수신 특권은 적절한 시스템 콜을 통해 다른 프로세스에 전달될 수 있다.
3.6.2. 동기화
프로세스 간 통신은 send와 receive 프리미티브에 대한 호출에 의해 발생한다.
각 프리미티브를 구현하기 위한 서로 다른 설계 옵션이 있다. 메시지 전달은 봉쇄형(blocking)이거나 비봉쇄형(nonblocking) 방식으로 전달된다. 이 두 방식은 각각 동기식, 비동기식으로도 알려져 있다.
- 봉쇄형 보내기: 송신하는 프로세스는 메시지가 수신 프로세스 또는 메일박스에 의해 수신될 때까지 봉쇄된다.
- 비봉쇄형 보내기: 송신하는 프로세스가 메시지를 보내고 작업을 재시작한다.
- 봉쇄형 받기: 메시지가 이용 가능할 때까지 수신 프로세스가 봉쇄된다.
- 비봉쇄형 받기: 송신하는 프로세스가 유효한 메시지 또는 널을 받는다.
send와 receive가 모두 봉쇄형일 때 송신자와 수신자 간에 랑데부를 하게 된다.
봉쇄형 send와 receive를 사용한다면 생산자와 소비자 문제에 대한 해결책은 사소한 문제가 된다.
생산자는 단순히 봉쇄형 send를 호출하고 메시지가 수신자 또는 메일박스에 전달될 때까지 기다린다.
소비자는 receive를 호출하면 메시지가 전달될 때까지 봉쇄된다.
3.6.3. 버퍼링
통신이 직접적이든 간접적이든 간에, 통신하는 프로세스들에 의해 교환되는 메시지는 임시 큐에 들어 있다.
기본적으로 이러한 큐를 구현하는 방식은 세 가지가 있다.
- 무용량(zero capacity): 큐의 최대 길이가 0이다. 즉, 링크는 자체 안에 대기하는 메시지들을 가질 수 있다. 이 경우, 송신자는 수신자가 메시지를 수신할 때까지 기다려야 한다.
- 유한 용량(bounded capacity): 큐는 유한한 길이 n을 가진다. 즉 최대 n개의 메시지가 그 안에 들어 있을 수 있다. 새로운 메시지가 전송될 때 큐가 가득 차 있지 않으면, 메시지는 큐에 놓이며 송신자는 대기하지 않고 실행을 계속한다. 큐가 가득 차 있으면, 송신자는 큐 안에 공간이 이용 가능할 때까지 반드시 봉쇄되어야 한다.
- 무한 용량(unbounded capacity): 큐는 잠재적으로 무한한 길이를 가진다. 따라서 메시지들이 얼마든지 큐 안에서 대기할 수 있으며, 송신자는 절대 봉쇄되지 않는다.
무용량의 경우 때때로 버퍼가 없는 메시지 시스템이라고 부르며, 다른 경우들은 자동 버퍼링이라 부른다.
3.7. IPC 시스템의 사례
3.7.1. POSIX 공유 메모리
POSIX 공유 메모리는 메모리-사상 파일을 사용하여 구현된다.
메모리-사상 파일은 공유 메모리의 특정 영역을 파일과 연관시킨다. 프로세스는 먼저 shm_open 시스템 콜을 사용하여 공유 메모리 객체를 생성해야 한다.
shm_open(name, O_CREAT | O_RDWR, 0666)- 첫 번째 인자는 공유 메모리 객체의 이름을 지정한다. 공유 메모리에 접근하고자 하는 프로세스는 이 이름을 통하여 객체를 언급한다.
- 두 번째 인자는 객체가 존재하지 않으면 생성되고, 읽기와 쓰기가 가능한 상태로 열린다는 것을 나타낸다.
- 세 번째 인자는 공유 메모리 객체에 파일-접근 허가권을 부여한다.
shm_open이 성공하면 공유 메모리 객체를 나타내는 정수형 파일 설명자를 반환한다.
객체가 설정되면 ftruncate 함수를 사용하여 객체의 크기를 바이트 단위로 설정한다.
ftruncate(fd, 4096)
마지막으로 mmap 함수가 공유 메모리 객체를 포함하는 메모리-사상 파일을 구축한다.
mmap 함수는 공유 메모리 객체에 접근할 때 사용될 메모리-사상 파일의 포인터를 반환한다.
예제의 프로그램은 공유 메모리를 구현하기 위해 생산자-소비자 모델을 사용한다.
생산자는 공유 메모리 객체를 구축하고 공유 메모리에 데이터를 쓴다.
- 생산자는 공유 메모리 객체를 메모리에 사상하고 객체에 쓰기 권한을 부여한다.
MAP_SHARED플래그는 공유 메모리 객체에 변경이 발생하면 객체를 공유하는 모든 프로세스가 최신의 값을 접근하게 된다는 것을 지정한다.- 공유 메모리 객체에 쓰기 작업을 성공하면 쓰인 바이트 수만큼 포인터를 반드시 증가시켜야 한다.
소비자는 공유 메모리에서 데이터를 읽는다.
shm_unlink함수를 호출하여 접근이 끝난 공유 메모리를 제거한다.
3.7.2. Mach 메시지 전달
Mach 커널은 프로세스와 유사하지만 제어 스레드가 많고 관련 자원이 적은 다중 태스크의 생성 및 제거를 지원한다.
모든 태스크 간 통신을 포함하여 Mach에서 대부분의 통신은 메시지로 수행된다.
Mach에서 포트라고 하는 메일박스로 메시지를 주고 받는다. 포트는 크기가 정해져 있고 단방향이다.
양방향 통신의 경우 메시지가 한 포트로 전송되고 응답이 별도의 응답 포트로 전송된다.
각 포트에는 여러 송신자가 있을 수 있지만 수신자는 오직 하나만 존재한다.
Mach는 포트를 사용하여 태스크, 스레드, 메모리 및 프로세서와 같은 자원을 나타내며, 메시지 전달은 이러한 시스템 자원 및 서비스와 상호 작용하기 위한 객체 지향 접근 방식을 제공한다.
동일한 호스트 또는 분산 시스템의 별도 호스트의 두 포트 사이에서 메시지 전달이 발생할 수 있다.
각 포트에는 그 포트와 상호 작용하는 데 필요한 자격을 식별하는 포트 권한 집합이 연관된다.
예를 들어, 태스크가 포트에서 메시지를 수신하려면 해당 포트에 대해 MACH_PORT_RIGHT_RECEIVE 자격이 있어야 한다.
포트를 생성한 태스크가 해당 포트의 소유자이며, 소유자는 해당 포트에서 메시지를 수신할 수 있는 유일한 태스크이다.
포트의 소유자는 포트의 자격을 조작할 수 있으며, 이러한 조작은 일반적으로 응답 포트를 설정할 때 수행한다.
포트 권한의 소유권은 태스크에게 주어지며, 동일한 태스크에 속하는 모든 스레드가 동일한 포트 권한을 공유한다.
태스크가 생성되면 Task Self 포트와 Notify 포트라는 두 개의 특별 포트가 생성된다.
커널은 Task Self 포트에 대한 수신 권한을 가지고 있어 태스크가 커널에 메시지를 보낼 수 있다.
커널은 이벤트 발생 알림을 테스크의 Notify 포트로 보낼 수 있다.
mach_port_allocate 함수 호출은 새 포트를 작성하고 메시지 큐를 위한 공간을 할당하며, 포트에 대한 권한을 식별한다.
각 포트 권한은 해당 포트의 이름을 나타내며 포트는 권한을 통해서만 액세스할 수 있다.
포트 이름은 단순한 정수 값이며 UNIX 파일 디스크립터와 매우 유사하게 작동한다.
각 태스크는 또한 부트스트랩 포트에 액세스할 수 있어서 태스크가 생성한 포트를 시스템 전체의 부트스트랩 서버에 등록할 수 있다.
포트가 부트스트랩 서버에 등록되면 다른 태스크가 이 레지스트리에서 포트를 검색하여 포트로 메시지를 보낼 수 있는 권한을 얻을 수 있다.
각 포트와 관련된 큐는 크기가 제한되어 있으며 처음에는 비어 있다. 메시지가 포트로 전송되면 큐에 복사된다.
모든 메시지는 안정적으로 전달되며 동일한 우선순위를 가진다. Mach는 동일한 송신자의 여러 메시지가 선입선출 순서로 큐에 삽입하지만 절대적 순서를 보장하지는 않는다.
Mach 메시지에는 다음 두 필드를 포함한다.
- 고정 크기의 메시지 헤더: 메시지 크기, 소스 및 대상 포트를 포함한 메시지에 관한 메타데이터
- 데이터를 포함하는 가변 크기 본체
메시지는 단순하거나 복잡할 수 있다.
간단한 메시지는 커널에 의해 해석되지 않는 구조화되지 않은 보통의 사용자 데이터를 포함한다.
복잡한 메시지는 out-of-line 데이터를 포함하는 메모리 위치에 대한 포인터를 포함하거나 다른 태스크에 포트 권한을 전송하는 데 사용될 수 있다.
out-of-line 데이터 포인터는 메시지가 많은 양의 데이터를 전달해야 할 때 특히 유용하다.
간단한 메시지는 메시지의 데이터를 복사하고 패키징해야 한다. out-of-line 데이터 전송에는 데이터가 저장된 메모리 위치를 가리키는 포인터만 필요하다.
mach_msg 함수는 메시지를 보내고 받는 표준 API이다.
함수의 매개변수 중 하나가 MACH_SEND_MSG 혹은 MACH_RCV_MSG 값을 가지며 송신 또는 수신 연산인지를 나타낸다.
mach_msg 함수 호출은 메시지 전달을 수행하기 위해 사용자 프로그램에 의해 호출된다.
이후 mach_msg는 mach_msg_trap 함수를 호출한다. 이는 Mach 커널에 대한 시스템 콜이다.
커널 내에서 mach_msg_trap은 mach_msg_overwrite_trap 함수를 호출하여 메시지의 실제 전달을 처리한다.
송수신 작업 자체는 융통성이 있다. 예를 들어, 메시지가 포트로 전송되었을 때 큐가 가득 차 있을 수 있다. 큐가 가득 차지 않으면 메시지는 큐에 복사되고 전송 작업이 계속된다.
포트의 큐가 가득 찬 경우 송신자는 mach_msg의 매개변수를 통해 다음 중 하나를 선택할 수 있다.
- 큐에 공간이 생길 때까지 무기한 기다린다.
- 최대 n 밀리초 동안 기다린다.
- 기다리지 않고 즉시 복귀한다.
- 메시지를 일시적으로 캐시한다. 메시지가 전송되는 큐가 가득 차더라도 운영체제에 전달하여 보존한다.
마지막 옵션은 서버 태스크를 위한 것이다. 요청을 완료한 후 서버 태스크는 서비스를 요청한 태스크에 일회성 요청을 보내야 한다.
그러나 클라이언트의 응답 포트가 가득 찬 경우에도 다른 서비스 요청을 계속 서비스해야 한다.
메시지 시스템의 주요 문제점은 일반적으로 송신자의 포트에서 수신자의 포트로 메시지를 복사해야 하므로 발생하는 성능 저하이다.
Mach 시스템 콜은 가상 메모리 관리 기술을 사용하여 복사 연산을 피하려고 한다. 기본적으로 Mach는 송신자의 메시지가 포함된 주소 공간을 수신자의 주소 공간에 매핑한다.
따라서 송신자와 수신자 모두 동일한 메모리에 액세스하므로 메시지 자체는 실제로 복사되지 않는다.
3.7.3. Windows
Windows 운영체제는 모듈화를 이용하여 기능을 향상시키고 새로운 기능을 구현하는 시간을 감소시킨 최신 설계의 예이다.
Windows는 다중 운영 환경 또는 서브시스템을 지원하며, 응용 프로그램은 메시지 전달 기법을 통해 이들과 통신한다.
따라서 응용 프로그램은 서버시스템 서버의 클라이언트로 간주할 수 있다.
Windows의 메시지 전달 설비는 고급 로컬 프로시저 호출 장비(ALPC; Advanced Local Procedure Call Facility)라 불린다.
ALPC는 동일 기계상에 있는 두 프로세스 간의 통신에 사용한다. 이것은 널리 사용되는 표준 원격 프로시저 호출(RPC; Remote Procedure Call)과 같으나, Windows에 맞게 특별히 최적화되었다.
Mach와 유사하게, Windows는 두 프로세스 간에 연결을 구축하고 유지하기 위해 포트 객체를 사용한다.
Windows는 연결 포트와 통신 포트의 두 가지 유형의 포트를 사용한다.
서버 프로세스는 모든 프로세스가 접근할 수 있는 연결 포트 객체를 공표한다.
클라이언트가 서브시스템으로부터 서비스를 원할 경우, 서버의 연결 포트 객체에 대한 핸들을 열고 연결 요청을 보낸다.
서버는 채널을 생성하고 핸들을 클라이언트에게 반환한다. 채널은 한 쌍의 사적인 통신 포트로 구성되는데, 하나는 클라이언트에서 서버로 메시지를 보내기 위한 포트이고 다른 하나는 서버에서 클라이언트로 메시지를 보내기 위한 포트이다.
통신 채널은 클라이언트와 서버가 응답 메시지를 기다리고 있는 동안에도 다른 요청을 받아들일 수 있도록 콜백 기법을 제공한다.
ALPC 채널이 생성되면 다음 3가지 중 하나의 메시지 전달 기법 중 하나가 선택된다.
- 256바이트까지의 작은 메시지의 경우 포트의 메시지 큐가 중간 저장소로 사용되고, 메시지는 프로세스에서 프로세스로 복사된다.
- 대용량 메시지는 반드시 세션 객체를 통하여 전달되어야 한다. 세션 객체는 채널과 관련된 공유 메모리의 영역이다.
- 데이터의 양이 너무 많아서 섹션 객체에 저장될 수 없는 경우, 서버 프로세스가 클라이언트의 주소 공간을 직접 읽거나 쓸 수 있는 API를 사용할 수 있다.
클라이언트는 채널을 설정할 때 대용량 메시지 전송이 필요한지 결정해야 한다. 클라이언트가 대용량 메시지를 보내야 한다고 결정하면 섹션 객체의 생성을 요청한다.
서버의 응답 메시지가 대용량이라고 예상되면 서버가 섹션 객체를 생성한다.
섹션 객체를 사용하려면 섹션 객체를 가리키는 포인터와 크기에 대한 정보를 담고 있는 작은 메시지가 전송된다. 이 방법은 첫 번째 방법보다 복잡하지만 데이터 복사가 발생하지 않는다.
Windows의 ALPC는 Windows API의 부분이 아니기 때문에 응용 프로그래머는 사용할 수 없다.
Windows API를 사용하는 응용은 RPC를 사용한다. 같은 시스템상에 존재하는 프로세스의 RPC가 호출되면 이 RPC는 간접적으로 ALPC를 통해 처리된다.
또한 많은 커널 서비스들은 클라이언트 프로세스와 통신하기 위하여 ALPC를 사용한다.
3.7.4. 파이프
파이프는 두 프로세스가 통신할 수 있게 하는 전달자로서 동작한다.
파이프는 초기 UNIX 시스템에서 제공하는 IPC 기법 중 하나였으며, 통상 프로세스 간에 통신하는 더 간단한 방법의 하나이지만 통신할 때 여러 제약이 따른다.
파이프를 구현하기 위해 다음 4가지 문제를 고려해야 한다.
- 파이프가 단방향 통신 또는 양방향 통신을 허용하는가?
- 양방향 통신을 허용한다면 반이중 방식인가, 전이중 방식인가?
- 통신하는 두 프로세스 간에 부모-자식 등의 특정 관계가 존재해야 하는가?
- 파이프는 네트워크를 통하여 통신이 가능한가, 혹은 동일한 기계 안에 존재하는 두 프로세스끼리만 통신할 수 있는가?
3.7.4.1. 일반 파이프
일반 파이프는 생산자-소비자 형태로 두 프로세스 간의 통신을 허용한다. 생산자는 파이프의 한 종단에 쓰고, 소비자는 다른 종단에서 읽는다.
결과적으로 일반 파이프는 한쪽으로만 데이터를 전송할 수 있으며 오직 단방향 통신만을 가능하게 한다.
양방향 통신이 필요하다면 각각 다른 방향으로 데이터를 전송할 수 있는 두 개의 파이프를 사용해야 한다.
UNIX 시스템에서 일반 파이프는 다음 함수를 사용하여 구축된다.
pipe(int fd[])- 이 함수는
fd[]파일 설명자를 통해 접근되는 파이프를 생성한다. fd[0]은 파이프의 읽기 종단이며fd[1]은 파이프의 쓰기 종단이다.- UNIX는 파이프를 파일의 특수한 유형으로 취급하며, 일반적인
read와write시스템 콜을 사용하여 접근할 수 있다.
일반 파이프는 파이프를 생성한 프로세스 이외에는 접근할 수 없다. 따라서 통상 부모 프로세스가 파이프를 생성하고 fork로 생성한 자식 프로세스와 통신하기 위해 사용한다. (자식 프로세스는 열린 파일을 부모로부터 상속받기 때문이다.)
파이프는 파일의 특수한 유형이므로 자식 프로세스는 부모로부터 파이프를 상속받는다.
부모 프로세스가 fork로 생성한 자식 프로세스에 파이프를 상속할 때, 부모 프로세스와 자식 프로세스 모두 처음에 자신들이 사용하지 않는 파이프의 종단을 닫는다.
writer가 파이프의 종단을 닫았을 때, 파이프로부터 읽는 프로세스가 end-of-file을 탐지하는 것을 보장하기 때문에 이 작업은 매우 중요한 절차이다.
Windows 시스템의 일반 파이프는 익명 파이프(Anonymous Pipe)라 불리며 UNIX의 대응되는 파이프와 유사하게 동작한다.
이 파이프는 단방향이고 통신하는 두 프로세스는 부모-자식 관계여야 한다.
파이프의 읽기와 쓰기는 보통의 ReadFile과 WriteFile 함수를 사용하여 이루어진다.
파이프를 생성하기 위한 Windows API는 CreatePipe 함수로서 4개의 매개변수를 전달받는다.
- 첫 번째 매개변수는 읽기(핸들 포인터)
- 두 번째 매개변수는 쓰기(핸들 포인터)
- 세 번째 매개변수는 자식 프로세스가 파이프의 핸들을 상속받는다는 것을 명시하기 위해 사용
- 네 번째 매개변수는 바이트 단위의 파이프의 크기가 지정될 수 있다.
Windows에서는 프로그래머가 어떤 속성을 상속받는지를 명시해야 한다.
우선 핸들을 상속받을 수 있도록 SECURITY_ATTIRUBTES 구조체를 초기화하고, 자식 프로세스의 표준 입력 또는 표준 출력 핸들을 파이프의 읽기 또는 쓰기 핸들로 재지정해야 한다.
자식 프로세스가 파이프로부터 읽도록 만들어야 하므로 부모 프로세스는 자식의 표준 입력을 파이프의 읽기 핸들로 재지정해야만 한다.
파이프는 반이중 방식이므로 자식이 파이프의 쓰기 종단을 상속받는 것을 금지시켜야 한다.
파이프에 쓰기 전에 부모는 먼저 파이프의 사용하지 않을 읽기 종단을 닫으며, 자식 프로세스는 파이프로부터 읽기 전에 GetStdHandle 함수를 호출하여 파이프의 읽기 핸들을 획득한다.
3.7.4.2. 이름 있는 파이프 (Named Pipe)
일반 파이프는 한 쌍의 프로세스가 통신할 수 있는 간단한 기법을 제공한다. 그러나 일반 파이프는 오로지 프로세스들이 서로 통신하는 동안에만 존재한다.
UNIX와 Windows 시스템 모두에서 프로세스들이 통신을 마치고 종료하면 일반 파이프는 없어지게 된다.
이름 있는 파이프는 좀 더 강력한 통신 도구를 제공한다.
통신은 양방향으로 가능하며 부모-자식 관계도 필요로 하지 않는다. 또한 여러 프로세스들이 이를 사용하여 통신할 수 있다.
통신 프로세스가 종료하더라도 이름 있는 파이프는 계속 존재하게 된다.
이름 있는 파이프를 UNIX에서는 FIFO라고 부른다.
FIFO가 생성되면 파이프는 파일 시스템의 보통 파일처럼 존재한다. mkfifo 시스템 콜을 이용하여 생성되고 일반적인 open, read, write, close 시스템 콜로 조작된다. 명시적으로 파일 시스템에서 삭제될 때까지 존재하게 된다.
FIFO는 양방향 통신을 허용하지만 반이중 전송만이 가능하다. 데이터가 양방향으로 전송될 필요가 있다면 보통 2개의 FIFO가 사용된다.
부가적으로 통신하는 두 프로세스는 동일한 기계 내에 존재해야 한다. 서로 다른 기계에 존재하는 프로세스 사이에 통신이 필요하다면 소켓을 사용해야 한다.
Windows 시스템의 이름 있는 파이프는 UNIX의 상응 파이프보다 훨씬 풍부한 통신 기법을 제공한다.
전이중 통신을 허용하며, 통신하는 두 프로세스는 같은 기계 또는 다른 기계상에 존재할 수 잇다.
UNIX FIFO는 바이트 단위 통신만을 허용하지만, Windows 시스템 파이프는 바이트 단위 혹은 메시지 단위 데이터 전송을 허용한다.
이름 있는 파이프는 CreateNamedPipe 함수를 사용하여 생성되고, 클라이언트는 ConnectNamedPipe 함수를 사용하여 이름 있는 파이프에 연결할 수 있다.
이름 있는 파이프를 위한 통신은 역시 ReadFile과 WriteFile 함수를 사용하여 실행된다.
3.8. 클라이언트-서버 환경에서의 통신
3.8.1. 소켓
소켓은 통신의 극점(Endpoint)를 뜨한다. 두 프로세스가 네트워크상에서 통신을 하려면 양 프로세스마다 하나씩, 총 두개의 소켓이 필요하다. 각 소켓은 IP 주소와 포트 번호 두 가지를 접합해서 구별한다.
일반적으로 소켓은 클라이언트-서버 구조를 사용한다. 서버는 지정된 포트에 클라이언트 요청 메시지가 도착하기를 기다리며, 요청이 수신되면 클라이언트 소켓으로부터 연결 요청을 수락하여 연결이 완성된다.
telnet, ftp 및 http 등의 특정 서비스를 구현하는 서버는 well-known 포트로부터 메시지를 기다린다.
예를 들면 SSH 서버는 22번, FTP 서버는 21번, HTTP 서버는 80번 포트를 사용한다. 1024 미만의 모든 포트는 well-known 포트로 간주되며 표준 서비스를 구현하는 데 사용된다.
클라이언트 프로세스가 연결을 요청하면 호스트 컴퓨터가 포트 번호를 부여한다. 이 번호는 1024보다 큰 임의의 정수가 된다.
두 호스트 사이에 패킷들이 오갈 때 그 패킷들은 이 목적지 포트 번호가 지정하는 데 따라 적절한 프로세스로 배달된다.
모든 연결은 유일해야 한다. 따라스 호스트 X에 있는 다른 클라이언트 프로세스가 동일한 웹 서버와 통신하면 그 클라이언트는 다른 포트 번호를 부여받게 된다.
Java는 세 가지 종류의 소켓을 제공한다.
- TCP 소켓은
Socket클래스로 구현된다. - UDP 소켓은
DatagramSocket클래스로 구현된다. MulticastSocket클래스는DatagramSocket클래스의 서브클래스로, 데이터를 여러 수신자에게 보낼 수 있다.
예제 프로그램은 TCP 소켓을 사용하는 date 서버를 설명한다. 클라이언트는 이 서버로부터 현재 날짜와 시간을 알아볼 수 있다.
예제에서는 서버가 포트 6013을 listen하고 있다. 연결이 수신되면 서버는 클라이언트에게 현재 날짜와 시간을 보내준다.
- 서버는 포트 6013을 listen 한다는 것을 지정하는
ServerSocket을 생성한다. accept메소드를 이용하여 listen하며, 클라이언트가 연결을 요청할 때까지 봉쇄된다.- 연결 요청이 들어오면
accept는 클라이언트와 통신하기 위해 사용할 수 있는 소켓을 반환한다.
클라이언트는 소켓을 생성하고 서버가 listen하는 포트와 연결함으로써 서버와 통신을 시작한다.
Socket을 생성하고 연결을 요청한다.- 연결되면 소켓은 일반적인 스트림 I/O 함수를 사용하여 소켓으로부터 읽을 수 있다.
소켓을 이용한 통신은 분산된 프로세스 간에 널리 사용되고 효율적이지만 너무 낮은 수준이다. 소켓은 스레드 간에 구조화되지 않은 바이트 스트림만을 통신하도록 하기 때문이다.
이러한 원시적인 바이트 스트림 데이터를 구조화하여 해석하는 것은 클라이언트와 서버의 책임이 된다.
3.8.2. 원격 프로시저 호출 (RPC)
원격 서비스와 관련한 가장 보편적인 형태 중 하나는 RPC 패러다임으로서, 네트워크에 연결된 두 시스템 사이의 통신에 사용하기 위하여 프로시저 호출 기법을 추상화하는 방법으로 설계되었다.
이것은 IPC와 많은 측면에서 유사하며 그러한 IPC 기반 위에 만들어진다. 그러나 여기서는 프로세스들이 서로 다른 시스템 위에서 돌아가기 때문에 원격 서비스를 제공하기 위해서는 메시지 기반 통신을 해야 한다.
IPC 방식과 달리 RPC 통신에 사용되는 메시지는 구조화되어 있고, 데이터의 패킷 수준을 넘어서게 된다.
각 메시지에는 원격지 포트에서 listen 중인 RPC daemon의 주소가 지정되어 있고 실행되어야 할 함수의 식별자, 그리고 그 함수에게 전달되어야 할 매개변수가 포함된다.
그런 후 요청된 함수가 실행되고 어떤 출력이든지 별도의 메시지를 통해 요청자에게 반환된다.
이 문맥에서 포트는 단순히 메시지 패키지의 시작 부분에 포함되는 정수이다.
시스템은 일반적으로 네트워크 주소는 하나씩 가지지만 그 시스템에서 지원되는 여러 서비스를 구별하기 위해 포트를 여러 개 가질 수 있다.
원격 프로세스가 어떤 서비스를 받고자 하면 그 서비스에 대응되는 적절한 포트 주소로 메시지를 보내야 한다.
RPC는 클라이언트가 원격 호스트의 프로시저를 호출하는 것을 마치 자신의 프로시저를 호출하는 것처럼 해준다.
RPC 시스템은 클라이언트 쪽에 스텁을 제공하여 통신을 하는 데 필요한 자세한 사항들을 숨겨준다. 보통 원격 프로시저마다 다른 스텁이 존재한다.
클라이언트가 원격 프로시저를 호출하면 RPC는 그에 대응하는 스텁을 호출하고 원격 프로시저가 필요로 하는 매개변수를 건네준다. 그러면 스텁이 원격 서버의 포트를 찾고 매개변수를 정돈(marshall)한다. 그 후 스텁은 메시지 전달 기법을 사용하여 서버에게 메시지를 전송한다.
이에 대응되는 스텁이 서버에도 존재하여 서버 측 스텁이 메시지를 수신한 후 적절한 서버의 프로시저를 호출한다. 필요한 경우 반환 값들도 동일한 방식으로 다시 되돌려준다.
Windows 시스템에서는 스텁 코드 MIDL(Microsoft Interface Definition Language)로 작성된 명세로부터 컴파일된다. 이 언어는 클라이언트와 서버 프로그램 사이의 인터페이스를 정의하는 데 사용된다.
매개변수 정돈(parameter marshalling)은 클라이언트와 서버 기기의 데이터 표현방식의 차이 문제를 해결한다.
32비트 정수로 예를 들어보자. 어떤 기계는 빅 엔디언 방식, 어떤 기계는 리틀 엔디언 방식을 사용할 수 있다.
이와 같은 차이를 해결하기 위해 대부분의 RPC 시스템은 기종 중립적인 데이터 표현 방식을 정의한다. 이러한 표현 방식 중 하나가 XDR(External Data Representation)이다.
클라이언트 측에서는 서버에게 데이터를 보내기 전 정돈 작업의 일환으로 전송할 데이터를 기종 중립적인 XDR 형태로 바꾸어서 보낸다. 수신측 기계에서는 XDR 데이터를 받으면 매개변수를 풀어내면서 자기 기종의 형태로 데이터를 바꾼 후 서버에게로 넘겨준다.
또 다른 중요한 문제는 호출의 의미에 관한 것이다.
지역 프로시저 호출의 경우 극단적인 경우에만 실패하지만 RPC의 경우는 네트워크 오류 때문에 실패할 수도 있고, 메시지가 중복되어 호출이 여러 번 실행될 수도 있다.
이 문제를 해결하는 방법은 운영체제가 메시지가 최대 한 번 실행되는 것이 아니라 정확히 한 번 처리되도록 보장하게 하는 것이다. 대부분의 지역 프로시저 홏룰은 정확히 한 번의 기능성을 가지고 있으나 이를 구현하는 것은 더 어렵다.
최대 한 번을 고려했을 때, 이 의미는 각 메시지에 타임스탬프를 매기는 것으로 보장할 수 있다.
서버는 이미 처리한 모든 메시지의 타임스탬프 기록을 가지거나 중복된 메시지를 검사해 낼 수 있을 만큼의 기록을 가져야 한다.
기록에 보관된 타임스탬프를 가진 메시지가 도착하면 그 메시지는 무시된다. 이렇게 하면 클라이언트는 한 번 이상 메시지를 보낼 수 있고, 메시지에 대한 실행이 단 한 번 실행된다는 것을 보장받을 수 있다.
정확히 한 번의 의미를 가지려면 서버가 요청을 받지 못하는 위험을 제거할 필요가 있다.
이를 완수하려면 서버는 위에서 설명한 최대 한 번 프로토콜을 구현하고 추가로 RPC 요청이 수신되었고 실행됐다는 응낙(Acknowledgement) 메시지를 보내야 한다.
이 ACK 메시지는 네트워킹에서 일반적이다. 클라이언트는 해당 호출에 대한 ACK를 받을 때까지 주기적으로 각 RPC 호출을 재전송해야 한다.
또 하나 다루어야 할 중요한 문제는 클라이언트와 서버 간의 통신 문제이다.
일반적인 프로시저 호출의 경우 바인딩이라는 작업이 링킹/적재/실행 시점에 행해진다. 이때 프로시저의 이름이 프로시저의 메모리 주소로 변환된다.
이와 마찬가지로 RPC도 클라이언트와 서버의 포트를 바인딩해야 하는데, 클라이언트는 서버의 포트번호를 어떻게 알 수 있는가? 두 시스템에는 모두 상대방에 대한 완전한 정보가 없다.
이를 위해 보통 두 가지 방법이 사용된다.
한 가지 방법은 고정된 포트 주소 혀태로 미리 정해 놓는 방법이다. 컴파일할 때 RPC에는 이 고정된 포트 번호를 준다. 컴파일 후에는 서버가 그 포트 번호를 임의로 바꿀 수 없다.
다른 방법은 랑데부 방식에 의해 동적으로 바인딩하는 방법이다. 보통 운영체제는 미리 정해져 있는 고정 RPC 포트를 통해 랑데부용 daemon(matchmaker)을 제공한다.
그러면 클라이언트가 자신이 실행하기를 원하는 RPC 이름을 담고 있는 메시지를 랑데부 daemon에게 보내서, RPC 이름에 대응하는 포트 번호가 무엇인지 알려달라고 요청한다.
그러면 포트 번호가 클라이언트에게 반환되고, 클라이언트는 그 포트 번호로 RPC 요청을 계속 보낸다.
RPC는 분산 파일 시스템(DFS; Distributed File System)을 구현하는 데 유용하다.
메시지가 원격지 DFS 서버 포트로 보내지고 이 서버는 File Operation을 실행해 준다.
메시지는 실행할 디스크 연산(read, write, rename, delete, status 등)을 포함한다.
DFS는 이 연산 결과를 클라이언트에게 반환 메시지로 보낸다.
3.8.2.1. Android RPC
RPC는 일반적으로 분산 시스템에서 클라이언트-서버 컴퓨팅과 관련되어 있지만 동일한 시스템에서 실행되는 프로세스 간 IPC의 형태로 사용될 수도 있다.
Android 운영체제는 바인더 프레임워크에 포함된 풍부한 IPC 기법의 집합을 가지고 있는데, 이 중 RPC는 프로세스가 다른 프로세스의 서비스를 요청할 수 있게 한다.
Android는 응용 프로그램 구성요소를 Android 응용 프로그램에 유용성을 제공하는 기본 빌딩 블록으로 정의하며, 앱은 여러 응용 프로그램 구성요소를 결합하여 필요한 기능을 구현할 수 있다.
이러한 응용 프로그램의 구성요소 중 하나는 사용자 인터페이스가 없지만 백그라운드로 실행되며 장기 실행 연산을 실행하거나 원격 프로세스에 대한 작업을 수행하는 서비스이다.
서비스의 예로는 백그라운드에서 음악을 재생하고 다른 프로세스가 실행 중단되는 것을 방지할 수 있다. 클라이언트 앱이 bindService 서비스 메소드를 호출하면 해당 서비스가 바운드되어 메시지 전달 또는 RPC를 사용하여 클라이언트-서버 통신을 제공할 수 있다.
바운드 서비스는 Android 클래스 Service를 상속해야 하며 클라이언트가 bindService를 호출할 때 호출되는 onBind 메소드를 구현해야 한다.
메시지 전달의 경우 onBind 메소드는 Messenger 서비스를 반환하며, 이 서비스는 클라이언트에서 서비스로 메시지를 보내는 데 사용된다.
Messenger 서비스는 단방향 통신만 가능하다. 서비스가 클라이언트에 응답을 보내야 하는 경우, 클라이언트도 Messenger 서비스를 제공해야 하며 서비스로 보내진 Message 객체의 replyTo 필드에 포함되어 제공된다. 그런 다음 서비스는 클라이언트에게 메시지를 보낼 수 있다.
RPC를 제공하기 위해 onBind 메소드는 클라이언트가 서비스와 상호 작용하기 위해 사용하는 원격 오브젝트 안에 메소드를 정의하는 인터페이스를 반환해야 한다.
이 인터페이스는 일반 Java 구문으로 작성되며 AIDL(Android Interface Definition Language)을 사용하여 스텁 파일을 생성한다. 이 스텁 파일이 원격 서비스에 대한 인터페이스 역할을 수행한다.